Machine Learning Pipeline: Architecture of ML Platform in Production

Machine learning (ML) history can be traced back to the 1950s when the first neural networks and ML algorithms appeared. But it took sixty years for ML became something an average person can relate to. Analysis of more than 16.000 papers on data science by MIT technologies shows the exponential growth of machine learning during the last 20 years pumped by big data and deep learning advancements.
Practically, with the access to data, anyone with a computer can train a machine learning model today. The automation capabilities and predictions produced by ML have various applications. That’s how modern fraud detection works, delivery apps predict arrival time on the fly, and programs assist in medical diagnostics.
Depending on the organization needs and the field of ML application, there will be a bunch of scenarios regarding how models can be built and applied. While the process of creating machine learning models has been widely described, there’s another side to machine learning — bringing models to the production environment. Models on production are managed through a specific type of infrastructure, machine learning pipelines. Here we’ll discuss functions of production ML services, run through the ML process, and look at the vendors of ready-made solutions.
What is a machine learning pipeline?
Machine learning is a subset of data science, a field of knowledge studying how we can extract value from data. ML in turn suggests methods and practices to train algorithms on this data to solve problems like object classification on the image, without providing rules and programming patterns. Basically, we train a program to make decisions with minimal to no human intervention. From a business perspective, a model can automate manual or cognitive processes once applied on production.
A machine learning pipeline (or system) is a technical infrastructure used to manage and automate ML processes in the organization. The pipeline logic and the number of tools it consists of vary depending on the ML needs. But, in any case, the pipeline would provide data engineers with means of managing data for training, orchestrating models, and managing them on production.
There is a clear distinction between training and running machine learning models on production. So, before we explore how machine learning works on production, let’s first run through the model preparation stages to grasp the idea of how models are trained.
Model preparation process
Technically, the whole process of machine learning model preparation has 8 steps. This framework represents the most basic way data scientists handle machine learning.

Data gathering: Collecting the required data is the beginning of the whole process. A dedicated team of data scientists or people with a business domain would define the data that will be used for training. According to François Chollet, this step can also be called “the problem definition.”
Data preparation and feature engineering: Collected data passes through a bunch of transformations. This is often done manually to format, clean, label, and enrich data, so that data quality for future models is acceptable. Once data is prepared, data scientists start feature engineering. Features are data values that the model will use both in training and in production. So, data scientists explore available data, define which attributes have the most predictive power, and then arrive at a set of features.
Algorithm choice: This one is probably done in line with the previous steps, as choosing an algorithm is one of the initial decisions in ML. At the heart of any model, there is a mathematical algorithm that defines how a model will find patterns in the data.
Model training: The training is the main part of the whole process. To train the model to make predictions on new data, data scientists fit it to historic data to learn from.
Testing and validating: Finally, trained models are tested against testing and validation data to ensure high predictive accuracy. Comparing results between the tests, the model might be tuned/modified/trained on different data. Training and evaluation are iterative phases that keep going until the model reaches an acceptable percent of the right predictions.
Deployment: The final stage is applying the ML model to the production area. So, basically the end user can use it to get the predictions generated on the live data.
Machine learning production pipeline
We’ve discussed the preparation of ML models in our whitepaper, so read it for more detail. But, that’s just a part of a process. After the training is finished, it’s time to put them on the production service.
The production stage of ML is the environment where a model can be used to generate predictions on real-world data. There are a couple of aspects we need to take care of at this stage: deployment, model monitoring, and maintenance. These and other minor operations can be fully or partially automated with the help of an ML production pipeline, which is a set of different services that help manage all of the production processes.
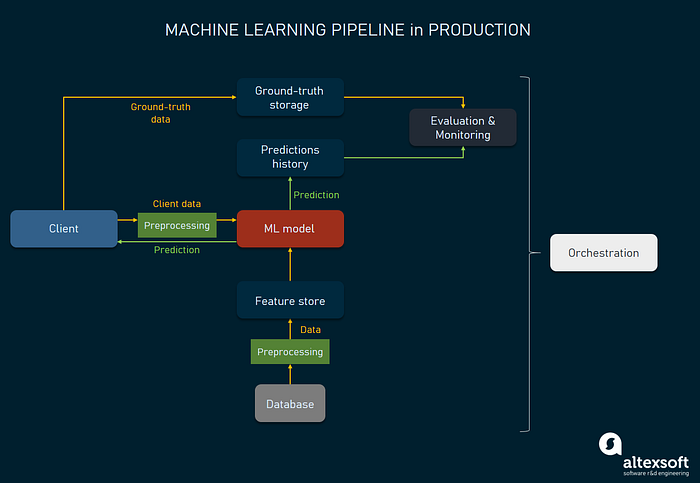
One of the key requirements of the ML pipeline is to have control over the models, their performance, and updates. Here we’ll look at the common architecture and the flow of such a system. We’ll segment the process by the actions, outlining main tools used for specific operations. Please keep in mind that machine learning systems may come in many flavors. The way we’re presenting it may not match your experience. However, this representation will give you a basic understanding of how mature machine learning systems work.
Triggering the model from the application client
To describe the flow of production, we’ll use the application client as a starting point. Given there is an application the model generates predictions for, an end user would interact with it via the client. A model would be triggered once a user (or a user system for that matter) completes a certain action or provides the input data. For instance, if the machine learning algorithm runs product recommendations on an eCommerce website, the client (a web or mobile app) would send the current session details, like which products or product sections this user is exploring now.
Application client: sends data to the model server.
Getting additional data from feature store
While data is received from the client side, some additional features can also be stored in a dedicated database, a feature store. This storage for features provides the model with quick access to data that can’t be accessed from the client. For example, if an eCommerce store recommends products that other users with similar tastes and preferences purchased, the feature store will provide the model with features related to that.
The feature store in turn gets data from other storages, either in batches or in real time using data streams. Batch processing is the usual way to extract data from the databases, getting required information in portions.
Data streaming is a technology to work with live data, e.g. sensor information that sends values every minute or so. For that purpose, you need to use streaming processors like Apache Kafka and fast databases like Apache Cassandra. While real-time processing isn’t required in the eCommerce store cases, it may be needed if a machine learning model predicts, say, delivery time and needs real-time data on delivery vehicle location.
Feature store: supplies the model with additional features.
Data preprocessing
The data that comes from the application client comes in a raw format. To enable the model reading this data, we need to process it and transform it into features that a model can consume. The process of giving data some basic transformation is called data preprocessing.
A feature store may also have a dedicated microservice to preprocess data automatically.
Data preprocessor: The data sent from the application client and feature store is formatted, features are extracted.
Generating predictions
Finally, once the model receives all features it needs from the client and a feature store, it generates a prediction and sends it to a client and a separate database for further evaluation.
Model: The prediction is sent to the application client.
Storing ground truth and predictions data
Another type of data we want to get from the client, or any other source, is the ground-truth data. This data is used to evaluate the predictions made by a model and to improve the model later on. We can call ground-truth data something we are sure is true, e.g. the real product that the customer eventually bought. A ground-truth database will be used to store this information.
However, collecting eventual ground truth isn’t always available or sometimes can’t be automated. For instance, the product that a customer purchased will be the ground truth that you can compare the model predictions to. But if a customer saw your recommendation but purchased this product at some other store, you won’t be able to collect this type of ground truth. Another case is when the ground truth must be collected only manually. If your computer vision model sorts between rotten and fine apples, you still must manually label the images of rotten and fine apples.
And obviously, the predictions themselves and other data related to them are also stored.
Ground-truth database: stores ground-truth data.
Monitoring and evaluating the model
The models operating on the production server would work with the real-life data and provide predictions to the users. What we need to do in terms of monitoring is
- ensure that accuracy of predictions remains high as compared to the ground truth.
- scrutinize model performance and throughput.
- understand whether the model needs retraining.
Monitoring tools are often constructed of data visualization libraries that provide clear visual metrics of performance. The interface may look like an analytical dashboard on the image.

There are some ground-works and open-source projects that can show what these tools are. E.g., MLWatcher is an open-source monitoring tool based on Python that allows you to monitor predictions, features, and labels on the working models.
Monitoring tools: provide metrics on the prediction accuracy and show how models are performing.
Orchestration
An orchestrator is basically an instrument that runs all the processes of machine learning at all stages. So, it enables full control of deploying the models on the server, managing how they perform, managing data flows, and activating the training/retraining processes.
Orchestrators are the instruments that operate with scripts to schedule and run all jobs related to a machine learning model on production. The popular tools used to orchestrate ML models are Apache Airflow, Apache Beam, and Kubeflow Pipelines.
Orchestration tool: sending commands to manage the entire process.
Machine learning model retraining pipeline
This is the time to address the retraining pipeline: The models are trained on historic data that becomes outdated over time. The accuracy of the predictions starts to decrease, which can be tracked with the help of monitoring tools. When the accuracy becomes too low, we need to retrain the model on the new sets of data. This process can also be scheduled eventually to retrain models automatically.

Model retraining
Retraining is another iteration in the model life cycle that basically utilizes the same techniques as the training itself. When the prediction accuracy decreases, we might put the model to train on renewed datasets, so it can provide more accurate results. In other words, we partially update the model’s capabilities to generate predictions. This doesn’t mean though that the retraining may suggest new features, removing the old ones, or changing the algorithm entirely. Retraining usually entails keeping the same algorithm but exposing it to new data. However, it’s not impossible to automate full model updates with autoML and MLaaS platforms.
All of the processes going on during the retraining stage until the model is deployed on the production server are controlled by the orchestrator. So, we can manage the dataset, prepare an algorithm, and launch the training. A model builder is used to retrain models by providing input data. Basically, it automates the process of training, so we can choose the best model at the evaluation stage.
Orchestration tool: sending models to retraining. Forming new datasets. Sourcing data collected in the ground-truth databases/feature stores.
Model builder: retraining models by the defined properties.
Contender model evaluation and sending it to production
Before the retrained model can replace the old one, it must be evaluated against the baseline and defined metrics: accuracy, throughput, etc.
An evaluator is a software that helps check if the model is ready for production. It may provide metrics on how accurate the predictions are, or compare newly trained models to the existing ones using real-life and the ground-truth data. The results of a contender model can be displayed via the monitoring tools. If a contender model improves on its predecessor, it can make it to production. The loop closes.
Evaluator: conducting the evaluation of the trained models to define whether it generates predictions better than the baseline model.
Orchestrator: pushing models into production.
Tools for building machine learning pipelines
A machine learning pipeline is usually custom-made. But there are platforms and tools that you can use as groundwork for this. Let’s have just a quick look at some of them to grasp the idea.
Google ML Kit. Deploying models in the mobile application via API, there is the ability to use Firebase platform to leverage ML pipelines and close integration with Google AI platform.
Amazon SageMaker. A managed MLaaS platform that allows you to conduct the whole cycle of model training. SageMaker also includes a variety of different tools to prepare, train, deploy and monitor ML models. One of the key features is that you can automate the process of feedback about model prediction via Amazon Augmented AI.
TensorFlow was previously developed by Google as a machine learning framework. Now it has grown to the whole open-source ML platform, but you can use its core library to implement in your own pipeline. A vivid advantage of TensorFlow is its robust integration capabilities via Keras APIs.
Challenges with updating machine learning models
While retraining can be automated, the process of suggesting new models and updating the old ones is trickier. In traditional software development, updates are addressed by version control systems. They divide all the production and engineering branches. In case anything goes wrong, it helps roll back to the old and stable version of a software.
Updating machine learning models also requires thorough and thoughtful version control and advanced CI/CD pipelines. However, updating machine learning systems is more complex. If a data scientist comes up with a new version of a model, most likely it has new features to consume and a wealth of other additional parameters.
For the model to function properly, the changes must be made not only to the model itself, but to the feature store, the way data preprocessing works, and more. Basically, changing a relatively small part of a code responsible for the ML model entails tangible changes in the rest of the systems that support the machine learning pipeline.
What’s more, a new model can’t be rolled out right away. It must undergo a number of experiments, sometimes including A/B testing if the model supports some customer-facing feature. During these experiments it must also be compared to the baseline, and even model metrics and KPIs may be reconsidered. Finally, if the model makes it to production, all the retraining pipeline must be configured as well.
As these challenges emerge in mature ML systems, the industry has come up with another jargon word, MLOps, which actually addresses the problem of DevOps in machine learning systems. This practice and everything that goes with it deserves a separate discussion and a dedicated article.
Originally published at AltexSoft tech blog “Machine Learning Pipeline: Architecture of ML Platform in Production”
